参考博客:https://blog.csdn.net/dai451954706/article/details/50464036
起初一直以为是导出的jar包有问题,百度了很久也没找到解决办法,最后终于让我找到了有用的解决办法。
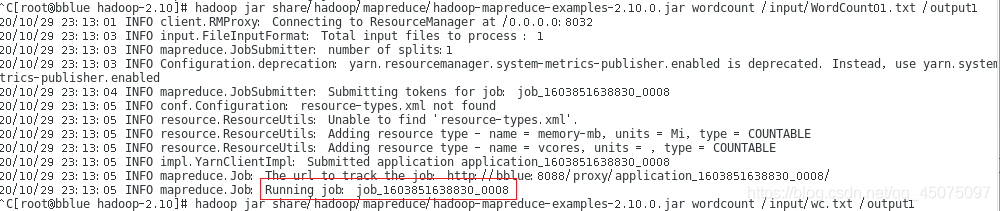
在yarn-site.xml中添加
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>20480</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property>我改完这个配置文件之后再次运行,发现还是处于Running job的状态,然后在mapred-site.xml中把下面几行配置删掉
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>然后再次执行就成功了
热门文章
- 上海农业大学动物医院官网(上海农业大学动物医院官网招聘)
- 免费Clash节点 | 2月21日21M/S|免费SSR/V2ray/Shadowrocket/Clash免费节点订阅分享
- 免费Clash节点 | 2月22日19.6M/S|免费V2ray/Shadowrocket/SSR/Clash免费节点订阅分享
- hadoop运行jar包处理文件一直处于Running job状态的解决方法
- 免费Clash节点 | 2月16日18.8M/S|免费Shadowrocket/SSR/Clash/V2ray免费节点订阅分享
- 免费Clash节点 | 2月19日20.3M/S|免费SSR/V2ray/Clash/Shadowrocket免费节点订阅分享
- 【和弦图】
- 上海地区宠物领养中心地址 上海地区宠物领养中心地址查询
- 宠物粮食店铺图片高清 宠物粮食店铺图片高清大图
- 免费Clash节点 | 2月20日23M/S|免费SSR/V2ray/Clash/Shadowrocket免费节点订阅分享
归纳
-
22 2025-02